Advanced data mapping
Standard data mapping
A common Tray.io scenario is that you need to simply pass data from one service to another, without necessarily needing to carry out any 'transformation' of the data.
In this case we will generally have to allow for the fact that fields have different names in each service. For example:

A simple way to carry out this kind of mapping is to use the Data Mapper
If you are dealing with a single object, the 'map keys' operation can be used.
However, in the above case where you have an array of data, you will need to use the 'map objects' operation.
In both cases you will use the Mapping field to set a 'mapping table' to meet your requirements:
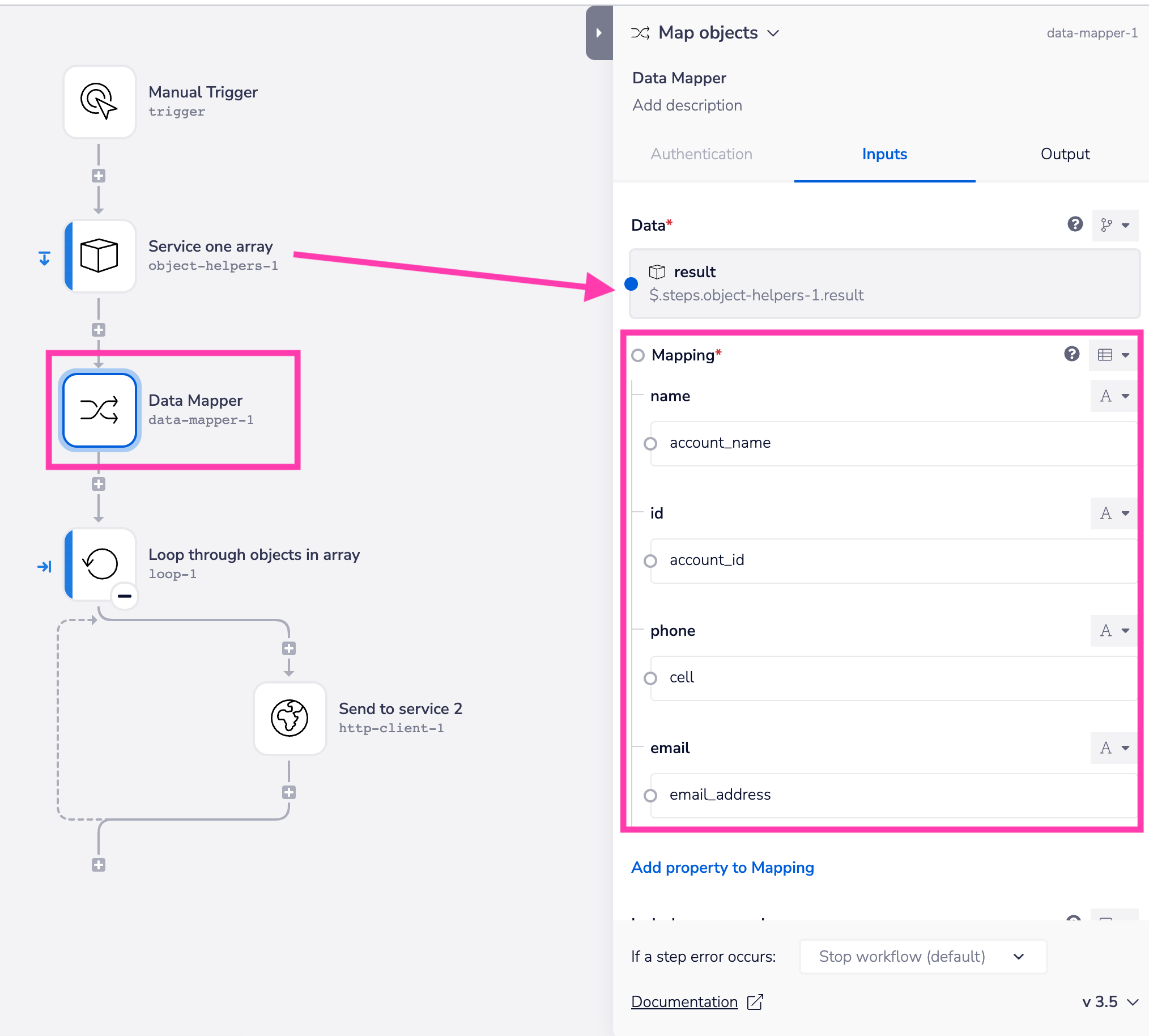
Unless the destination service has a 'batch create / update' operation (e.g. Salesforce), you will need to loop through the result from the data mapper and send each item in a series of single requests (in which case you will need to be aware of the need to queue your requests in order not to exceed API limits)
Mapping data between multiple systems
The above video takes you through a method of setting up data mapping that can scale across your company's tech stack.
It shows how you can set up a mapping system which can deal with mapping to multiple systems, by using Google Sheets (or other similar tools such as Airtable) as a lookup table for your defined mappings.
The following diagram illustrates an ingested payload which is then mapped to multiple systems.
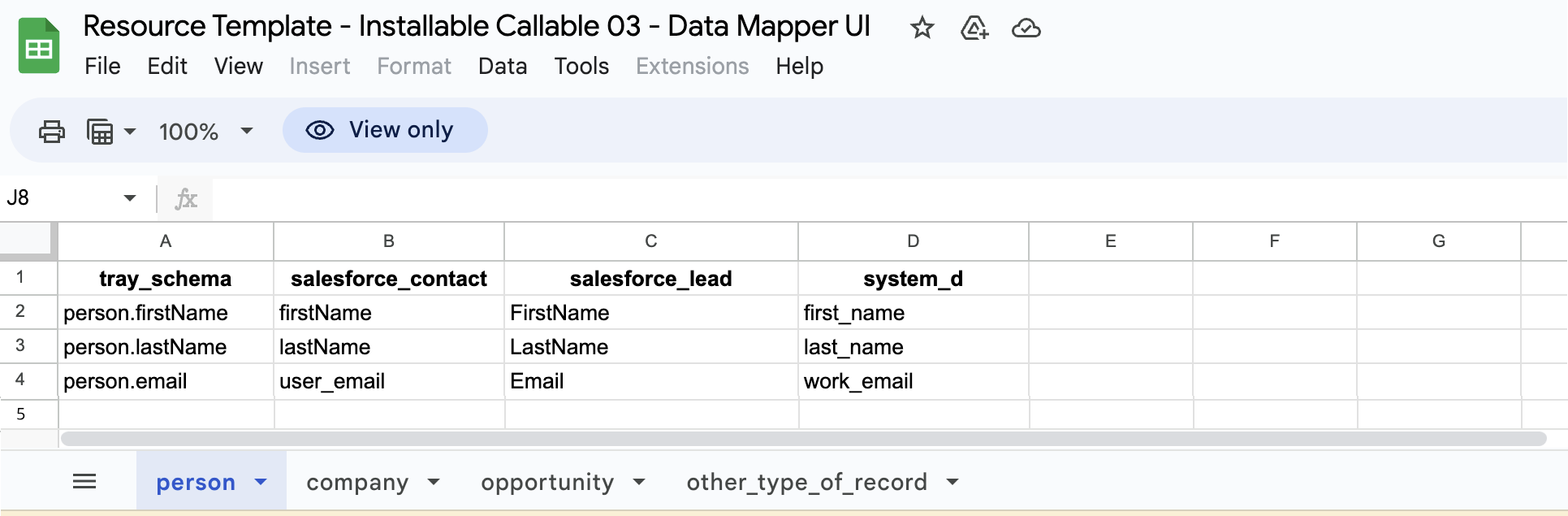
As you can see, one system uses 'camel case' firstName and lastName, while one uses 'snake case' first_name and last_name:

And the following screenshot shows how easy it is to store these mappings in Google Sheets:
How it works
Data ingestion
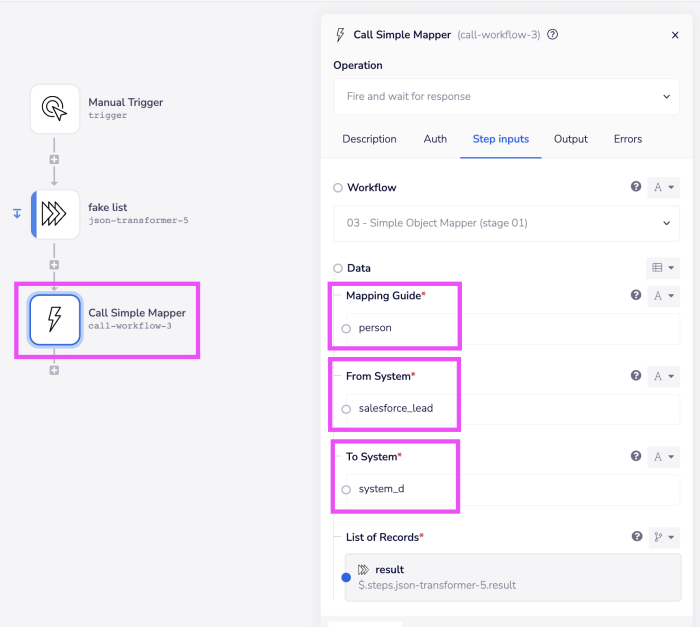
Any workflow which ingests data can be used to:
- Set the data object to be mapped (person, company, opportunity etc.)
- Set the 'from' system
- Set the 'to' system
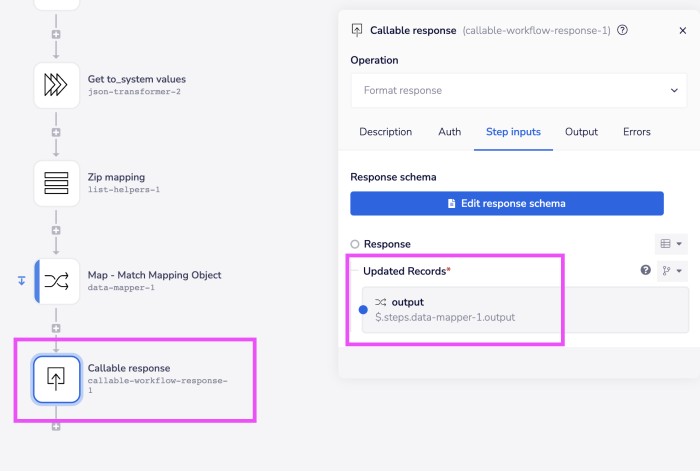
This is done when calling the workflow which actually carries out the mapping:
Data mapping
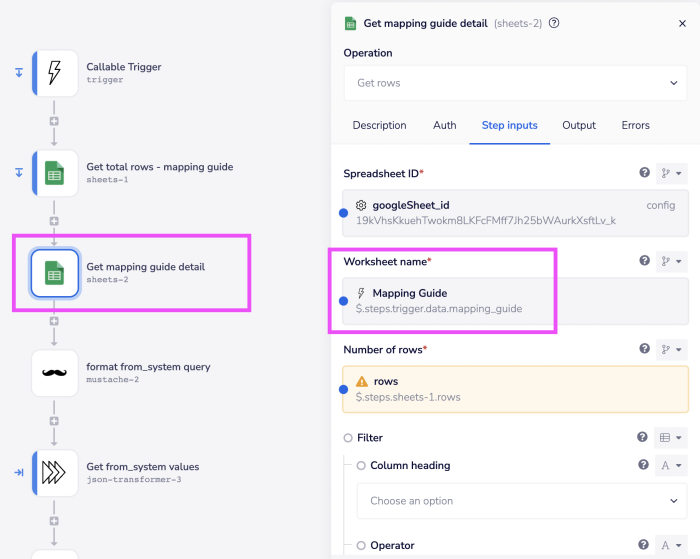
The mapping workflow which is called then:
Picks up the object type to be mapped from the trigger payload
Retrieves the schema for the 'To system'
Maps the payload received to the 'To system' schema
Allowing End Users to set their own mapping
Enterprise customers with the Embedded bundle may need to build integrations which allows their End Users to map data from one system to another.
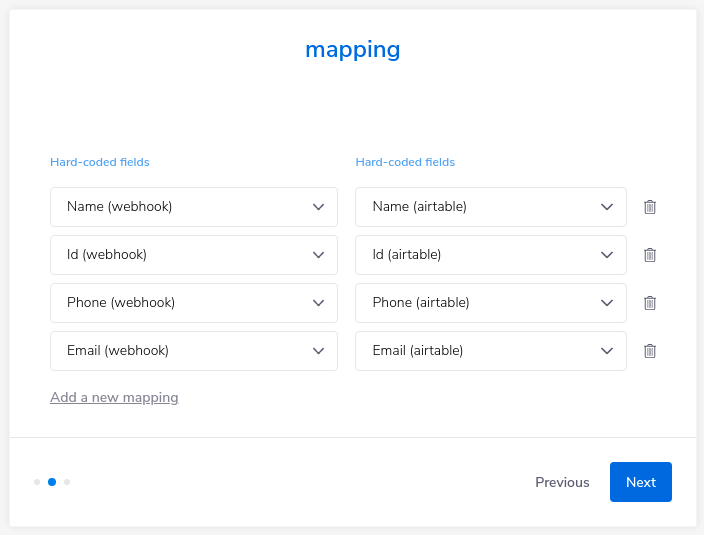
In this case, you can use the Config Wizard to allow your End Users to set up their own mapping tables.
In an Embedded Solution, amongst other things, you might allow your End Users to:
- Choose what services they want to map data to and from
- Choose a database table to map to
For the actual fields, you could then allow them to choose from a list of fields available in each service, as the required fields may differ from one End User to the next.
Please see our section on End User data mapping for full guidance on setting up data mapping for your End Users